So this week I decided I want to pick up the Deep Learning and AI course on coursera. It turns out there's a reason 700,000 people subscribed to the course, as it has 5 different courses, and spans somewhere between 3-6 months. I'm not sure what pace I'm going to be working this all through, but I guess we'll find out. In all honesty, I haven't had much time to work through this course yet as I only bought it on Friday, but I managed to go through the introduction sections.
I've always worked with neural networks in a high-level way, in that I could 'get it working' and solve a problem I was given at university, but often had very little understanding of what was actually going on. This wasn't to say I didn't understand what I was writing, but more that the exact principles behind what makes up a neural network were not clear to me. For example, one of the biggest projects I worked on recently was for suspicious activity detection in a video stream. During this project, I got a brief understanding of transfer learning, as I used an Xception CNN to perform image analysis of each frame to generate a feature vector, and then I used this feature vector to train a LSTM to detect if the video stream contained any suspicious activity. Unfortunately, as complex as that sounds, from my point of view it only really involved using an existing CNN model, developing around 100 lines of code for my LSTM, and spend a few days finding a good training and testing dataset. So while I can definitely say I can build some things with neural networks, I wouldn't really be able to go into detail about how they work.
Well the first week seems to focus on just providing a very high-level overview of neural networks. So far, I've gone through what a neural network is, and examples of how it can be used. This has meant learning the makeup of a basic NN, which is built up of layers that contain nodes, and how these nodes can connect to each other.
I also got a brief explanation of supervised learning with neural networks, which told me that generally supervised learning is broken down into either a standard NN (take inputs of X and predict a Y), a CNN (usually for image-related problems), an RNN (for sequence-related data), or a hybrid model that takes multiple types of data.
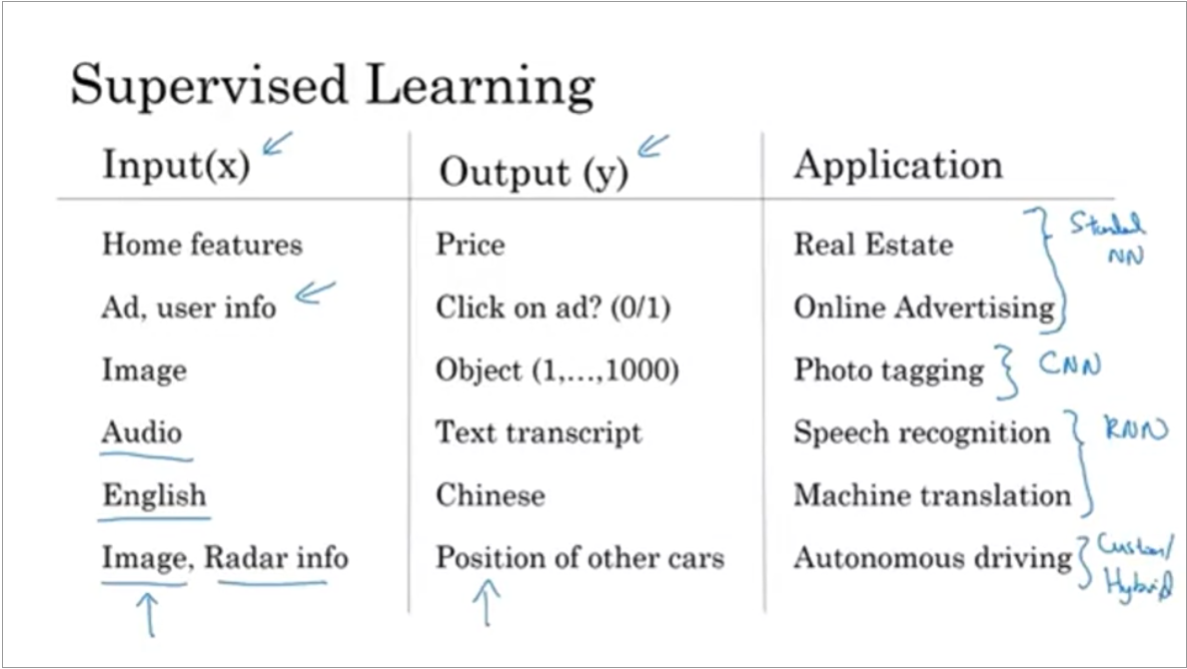
Finally, there was an introduction to the differences between structured and unstructured data, and a brief history of how computers have evolved to better understand unstructured data such as audio and images and text. I've always found structured data to be incredibly easy to use, but also that it came with its own obstacles, as the models I developed could sometimes feel a little restricted in their capacity to perform at scale as they had been trained on specific types of data. Training on unstructured data is more challenging, and therefore also more difficult to consistently provide good results with, but I feel like this is an area I hope to find out more about in this course, so that maybe I can get better at it.
In all honesty, this is all stuff I had already learnt at university (but I suppose it's a good start and it can't hurt to have a refresher on the fundamentals). Looking at the outline of the course though, it seems like week 2 will let me implement a lot of the algorithms discussed above, so hopefully I'll have more to add then.