In machine learning, overfitting is a common problem where a model learns the noise in the training data to the extent that it negatively impacts its performance on new, unseen data. Regularization techniques are used to prevent overfitting and improve the generalization ability of a model. In this blog post, we will explore two popular regularization methods: Ridge (L2) and Lasso (L1) regression.
Ridge regression, also known as L2 regularization, addresses the overfitting problem by adding a penalty term to the ordinary least squares objective function. The penalty term is the sum of the squared coefficients multiplied by a regularization parameter (λ). The objective function for ridge regression is:
where is the actual value, is the predicted value, is the coefficient of the -th feature, and is the regularization parameter. By adding this penalty term, ridge regression shrinks the coefficients towards zero, but they never reach exactly zero. This allows the model to retain all the features while reducing their impact on the predictions. The optimal value of is typically determined using cross-validation techniques, such as k-fold cross-validation.
Ridge regression can also be applied to models with discrete variables. For example, when predicting the influence of diet on the size of mice, the regularization term would be the sum of the squared differences in means between the high-fat diet and the normal diet groups, multiplied by .
Ridge regularization can be applied to logistic regression by adding the penalty term to the log-likelihood function. The objective function becomes:
where is the binary target variable, is the value of the -th feature for the -th instance, and is the coefficient of the -th feature.
The key difference between lasso and ridge regression is that lasso can drive some coefficients to exactly zero, effectively performing feature selection. This property makes lasso regression useful for identifying and removing irrelevant or redundant features from the model.
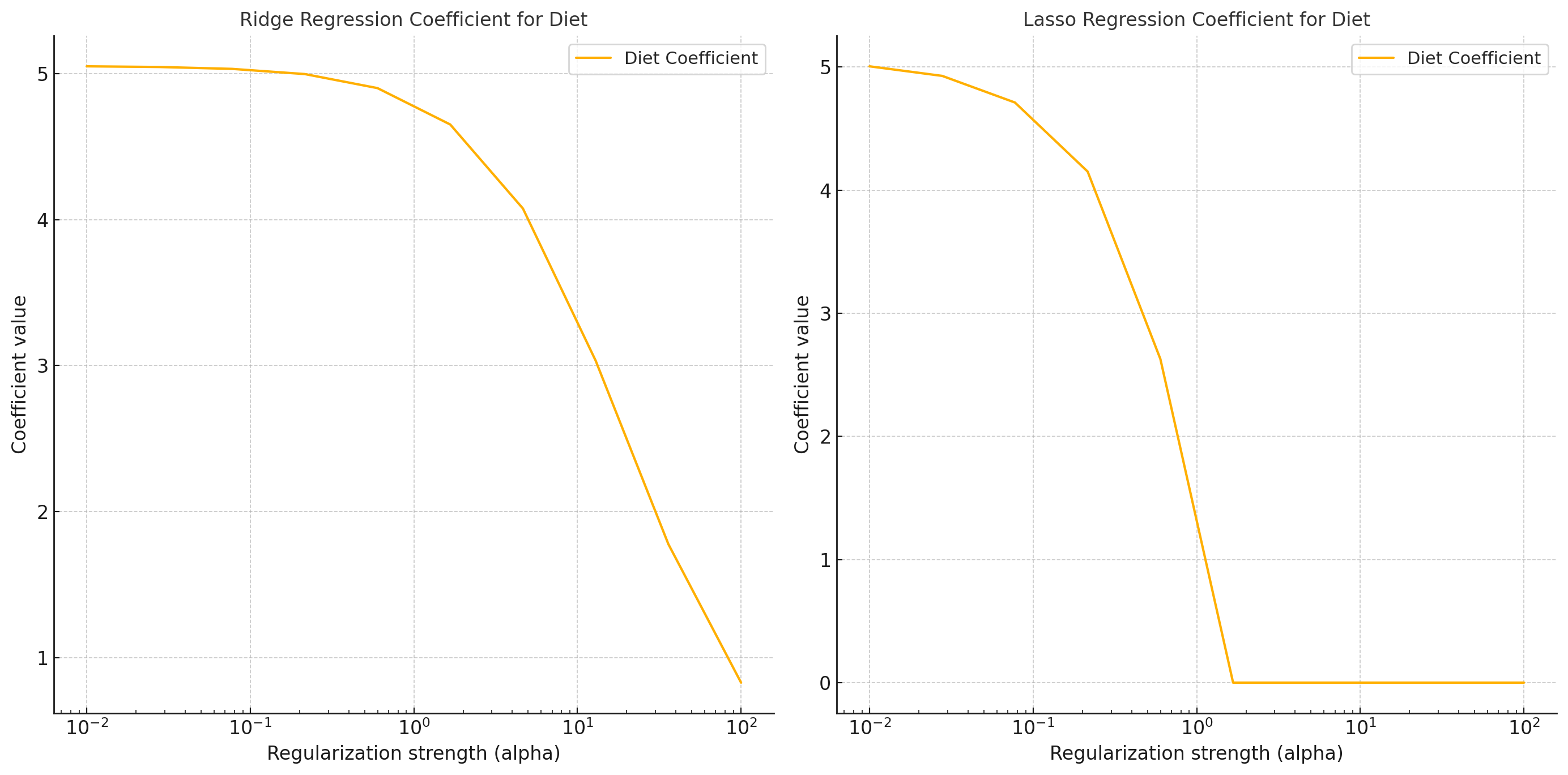
Regularization techniques, such as ridge and lasso regression, are essential tools for preventing overfitting and improving the generalization performance of machine learning models. Ridge regression shrinks the coefficients towards zero, while lasso regression can drive some coefficients to exactly zero, performing feature selection. By understanding and applying these regularization methods, you can build more robust and interpretable models that better handle unseen data.